
NJU-OS-Lab总结
M1:实现打印进程树状信息的工具 pstree
这个实验整体比较简单,就是去遍历/proc目录下所有数字开头的子目录,通过读取其中的status文件获取它们的进程号、父进程号和名称。我是先将这些信息存在链表中,读取完之后再将链表转换为树,进而格式化打印。
唯一可能要注意的是,得给存放进程名称的char数组长度给够,否则容易出错。
#include <assert.h>
#include <dirent.h>
#include <memory.h>
#include <stdarg.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
// 树状节点用于存储进程信息
typedef struct TreeNode {
int id;
char name[64];
struct TreeNode **children;
int num;
} TreeNode;
// 释放树节点内存
void freeTreeNode(TreeNode *node, int recursive_flag) {
if (node != NULL) {
// 由于所有的树节点实际是连续存放在一起的,因此只需要递归的释放存储子节点地址的children指针即可。
for (int i = 0; i < node->num; i++) {
freeTreeNode(node->children[i], recursive_flag);
}
free(node->children);
node->children = NULL;
}
}
// 查找数组中ID为id的元素序号
int findId(TreeNode *arr, int len, int id) {
for (int i = 0; i < len; i++) {
if (arr[i].id == id) {
return i;
}
}
return -1;
}
// 按Id从小到大排序子树节点
void sortTreeNode(TreeNode *node, int recursive_flag) {
if (node != NULL) {
if (recursive_flag) {
for (int i = 0; i < node->num; i++) {
sortTreeNode(node->children[i], recursive_flag);
}
}
for (int i = 0; i < node->num; i++) {
for (int j = i + 1; j < node->num; j++) {
if (node->children[i]->id > node->children[j]->id) {
TreeNode *tmp = node->children[i];
node->children[i] = node->children[j];
node->children[j] = tmp;
}
}
}
}
}
// 链表节点用于遍历文件夹是存储信息
typedef struct ListNode {
int pid;
int ppid;
char name[64];
struct ListNode *next;
} ListNode;
// 构造新链表节点
ListNode *newListNode(int pid, int ppid, char *name) {
ListNode *node = (ListNode *)malloc(sizeof(ListNode));
if (node == NULL) {
dPrintf("newListNode: malloc failed\n");
return NULL;
}
node->pid = pid;
node->ppid = ppid;
strcpy(node->name, name);
node->next = NULL;
return node;
}
// 删除链表节点
void freeListNode(ListNode *node, int recursive_flag) {
if (node != NULL) {
freeListNode(node->next, recursive_flag);
free(node);
node = NULL;
}
}
// 遍历/proc文件夹,并返回进程数
int traverseProc(ListNode *dummy) {
DIR *dir;
struct dirent *entry;
struct stat statbuf;
// 打开目录
if ((dir = opendir("/proc")) == NULL) {
fprintf(stderr, "Cannot open directory: %s\n", "/proc");
return -1;
}
int ret = 0;
// 读取目录内容
while ((entry = readdir(dir)) != NULL) {
// 获取文件或目录的信息
lstat(entry->d_name, &statbuf);
if (S_ISDIR(statbuf.st_mode)) {
// 子目录为.或..直接跳过
if (strcmp(".", entry->d_name) == 0 || strcmp("..", entry->d_name) == 0) {
continue;
}
// 判断子目录是否为数字目录
int is_num = 1;
for (int i = 0; i < 256 && entry->d_name[i] != '\0'; i++) {
if (entry->d_name[i] < '0' || entry->d_name[i] > '9') {
is_num = 0;
break;
}
}
if (is_num != 1) {
continue;
}
// 如果是数字目录,则读取/proc/pid/status文件
char path[256];
strcpy(path, "/proc/");
strcat(path, entry->d_name);
strcat(path, "/status");
FILE *fp = fopen(path, "r");
if (!fp) {
// 错误处理
dPrintf("traverseProc: cannot open file: %s\n", path);
continue;
}
// 读取Name和PPid
char buf[256];
ListNode *node = newListNode(atoi(entry->d_name), 0, "");
while (fgets(buf, sizeof(buf), fp)) {
if (strncmp(buf, "Name:", 5) == 0) {
int pos = 5;
// 去除Name开头可能的\b或\t
while (pos < sizeof(buf) && (buf[pos] == ' ' || buf[pos] == '\t')) {
pos += 1;
}
strcpy(node->name, buf + pos);
// 去除Name末尾可能的\n或\r
for (int i = 0; i < sizeof(node->name); i++) {
if (node->name[i] == '\n' || node->name[i] == '\r') {
node->name[i] = '\0';
break;
}
}
} else if (strncmp(buf, "PPid:", 5) == 0) {
int pos = 5;
while (pos < sizeof(buf) && buf[pos] == ' ') {
pos += 1;
}
node->ppid = atoi(buf + pos);
}
}
// 将新节点插入链表中
if (dummy->next != NULL) {
node->next = dummy->next;
}
dummy->next = node;
ret += 1;
fclose(fp);
}
}
// 关闭目录
closedir(dir);
// 返回进程数量
return ret;
}
// 根据链表构造树
TreeNode *constructTree(int len, TreeNode *treeArr, ListNode *head,
int numeric_sort) {
if (len <= 0 || treeArr == NULL || head == NULL) {
dPrintf("constructTree: invalid arguments\n");
return NULL;
}
// Info用于储存每个树节点有几个子节点
typedef struct Info {
int id;
int num;
} Info;
// 初始化 infoArr
Info *infoArr = (Info *)malloc(sizeof(Info) * (len + 1));
if (infoArr == NULL) {
return NULL;
}
memset(infoArr, 0, sizeof(Info) * (1 + len));
// 遍历链表,初始化树节点
int t = 0;
ListNode *p = head;
while (t < len && p != NULL) {
treeArr[t].id = p->pid;
strcpy(treeArr[t].name, p->name);
for (int i = 0; i <= len; i++) {
if (infoArr[i].id == p->ppid) {
infoArr[i].num += 1;
break;
}
if (infoArr[i].id == 0 && infoArr[i].num == 0) {
infoArr[i].id = p->ppid;
infoArr[i].num = 1;
break;
}
}
p = p->next;
t += 1;
}
// 根据infoArr,给每个树节点children分配内存
for (int i = 0; i <= len; i++) {
if (infoArr[i].id == 0) {
continue;
}
for (int t = 0; t < len; t++) {
if (infoArr[i].id == treeArr[t].id) {
treeArr[t].num = infoArr[i].num;
treeArr[t].children =
(TreeNode **)malloc(sizeof(TreeNode *) * infoArr[i].num);
memset(treeArr[t].children, 0, sizeof(TreeNode *) * infoArr[i].num);
}
}
}
// 按父子关系,构造树
p = head;
while (p != NULL) {
if (p->ppid == 0) {
p = p->next;
continue;
}
int parent_idx = findId(treeArr, len, p->ppid);
int child_idx = findId(treeArr, len, p->pid);
if (parent_idx == -1 || child_idx == -1) {
dPrintf(
"findId: fail to find a node,{ppid: %d, parent_idx: %d, pid: %d, "
"child_idx: %d}\n",
p->ppid, parent_idx, p->pid, child_idx);
return NULL;
}
for (int i = 0; i < treeArr[parent_idx].num; i++) {
if (treeArr[parent_idx].children[i] == NULL) {
treeArr[parent_idx].children[i] = treeArr + child_idx;
break;
}
}
p = p->next;
}
// 找到根节点并返回
TreeNode *root = NULL;
if (findId(treeArr, len, 1) != -1) {
root = treeArr + findId(treeArr, len, 1);
}
// 若numeric_sort为真,则需要每个树节点中子节点按id排序
if (numeric_sort) {
sortTreeNode(root, 1);
}
return root;
}
// 打印树状进程信息
void printInfo(TreeNode *root, int level, int show_pids) {
if (root == NULL) {
dPrintf("printInfo: root is NULL!\n");
return;
}
for (int i = 0; i < level; i++) {
printf("\t");
}
if (show_pids) {
printf("%s(%d)", root->name, root->id);
} else {
printf("%s", root->name);
}
for (int i = 0; i < root->num; i++) {
printf("\r\n");
printInfo(root->children[i], level + 1, show_pids);
}
return;
}
int main(int argc, char *argv[]) {
// 获取命令行参数
int show_pids = 0, numeric_sort = 0, version = 0;
for (int i = 0; i < argc; i++) {
assert(argv[i]);
dPrintf("argv[%d] = %s\n", i, argv[i]);
if (strcmp(argv[i], "-p") == 0 || strcmp(argv[i], "--show-pids") == 0) {
show_pids = 1;
}
if (strcmp(argv[i], "-n") == 0 || strcmp(argv[i], "--numeric-sort") == 0) {
numeric_sort = 1;
}
if (strcmp(argv[i], "-V") == 0 || strcmp(argv[i], "--version") == 0) {
version = 1;
}
}
assert(!argv[argc]);
// 若打印版本信息,则打印完版本信息后直接返回
// 反之,则显示当前线程信息
if (version == 1) {
printf(
"NanJing University Operating System Mini Lab1 1.0.0 \
Copyright (C) 1993-2020 Zhytou\n");
return 0;
}
ListNode *dummy = newListNode(-1, -1, "");
// 遍历/proc获取进程信息
int len = traverseProc(dummy);
// 初始化 treeArr
TreeNode *treeArr = (TreeNode *)malloc(sizeof(TreeNode) * len);
if (treeArr == NULL) {
dPrintf("main: fail to malloc treeArr!\n");
return 0;
}
memset(treeArr, 0, sizeof(TreeNode) * len);
// 构造树状进程信息
TreeNode *root = constructTree(len, treeArr, dummy->next, numeric_sort);
// 格式化打印信息
printInfo(root, 0, show_pids);
// 释放内存
freeListNode(dummy, 1);
freeTreeNode(root, 1);
free(treeArr);
treeArr = NULL;
return 0;
}
M2:实现协程库 libco
协程
理解协程:
在开始做本实验之前,我认为可以先阅读一些材料来认识进程、线程和协程之间的关系,比如这一篇Process , Thread and Coroutines。当我们能够认识到协程其实就是调度由用户管理的轻量级线程,即:用户态线程时,实验说明中的大部分内容就很好理解了。
至于协程结构体,则可以直接使用实验讲义中给出的,具体如下:
// 协程状态
enum co_status {
CO_NEW = 1, // 新创建,还未执行过
CO_RUNNING, // 已经执行过
CO_WAITING, // 在 co_wait 上等待
CO_DEAD, // 已经结束,但还未释放资源
};
// 协程
struct __attribute__((aligned(16))) co {
char *name;
void (*func)(void *); // co_start 指定的入口地址和参数
void *arg;
enum co_status status; // 协程的状态
struct co *waiter; // 是否有其他协程在等待当前协程
jmp_buf context; // 寄存器现场 (setjmp.h)
unsigned char stack[STACK_SIZE]; // 协程的堆栈
};
管理协程:
libco中应该记录当前执行协程以及当前所有协程,以便选择协程切换和保存当前协程状态。其中,我用来记录所有协程的数据结构是链表,实现如下:
// 当前运行协程,默认是main
struct co *current = NULL;
// 当前所有协程表
struct co_mgr_node *co_mgr_head = NULL;
// 协程管理,用链表存储当前上下文所有协程
struct co_mgr_node {
struct co *val;
struct co_mgr_node *next;
};
资源初始化和释放:
定义__attribute__((constructor))属性和__attribute__((destructor))属性的函数,保证在main函数执行之前正确初始化资源,在main函数 结束之后释放资源。
// co_mgr_head和current初始化,main函数执行前调用
static __attribute__((constructor)) void co_constructor(void) {
// 创建主线程,并将其加入到协程管理表中
current = co_start("main", NULL, NULL);
if (current == NULL) {
debug_printf("co_start main failed\n");
return;
}
current->status = CO_RUNNING;
}
// co_mgr_head和current释放,main函数执行后调用
static __attribute__((destructor)) void co_destructor(void) {
struct co_mgr_node *curr = co_mgr_head;
while (curr != NULL) {
struct co_mgr_node *next = curr->next;
free(curr->val);
free(curr);
curr = next;
}
co_mgr_head = NULL;
current = NULL;
}
上下文切换
理解setjmp/logjmp:
setjmp和longjmp是C语言中的非局部跳转函数,它可以实现函数间的非顺序调用。其中,setjmp的功能是:
- 保存当前函数的执行环境/寄存器状态到jmp_buf结构体数据类型变量中
- 函数返回值为0 longjmp的功能是:
根据jmp_buf结构体数据跳到之前使用setjmp保存的函数环境中 参数决定返回值是否为0
实现co_field:
setjmp和longjmp是C语言提供的非局部跳转机制。一般来说,使用它们实现跳转的方法如下:
- 使用setjmp保存当前执行环境到jmp_buf,然后默认返回0。
- 程序继续执行,到某个地方调用longjmp,传入上面保存的jmp_buf,以及另一个值。
- 此时执行点又回到调用setjmp的返回处,且返回值变成longjmp设置的值。
在理解了setjmp/logjmp的作用之后实现上下文切换就很容易了,具体实现如下:
// 切换协程
void co_yield () {
int ret = setjmp(current->context);
// 若ret为0,即为第一次设置jmp_buf(可以使用longjmp函数恢复寄存器状态),切换到一个新建或运行中的协程执行
// 否则为longjmp函数调用,直接返回
if (ret == 0) {
// 找到一个可以切换的协程
struct co *co = get_random_available_co(co_mgr_head);
if (co->status == CO_NEW) {
// 切换上下文,执行current->func
((volatile struct co *)co)->status = CO_RUNNING;
stack_switch_call(co->stack + STACK_SIZE, co->func, co->arg);
// 恢复寄存器状态
restore_registers_call();
((volatile struct co *)co)->status = CO_DEAD;
// 修改等待协程的状态
if (co->waiter != NULL) {
co->waiter->status = CO_RUNNING;
}
//
co_yield ();
} else if (co->status == CO_RUNNING) {
longjmp(co->context, 1);
}
}
return;
}
实现stack_swicth_call与restore_registers_call:
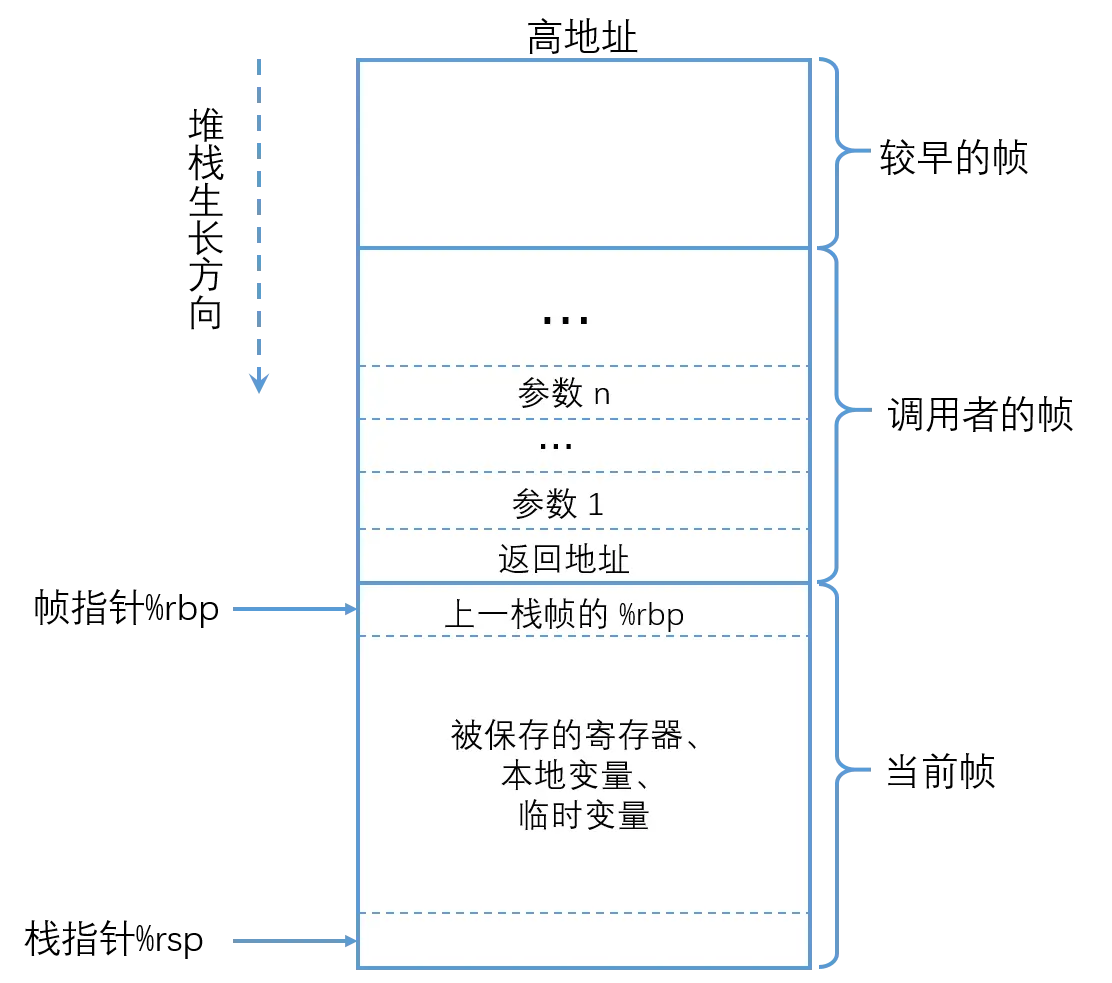
// 首先将call preserved registers保存下来
// 接着将堆栈寄存器和参数寄存器的值设为sp和arg,并跳转到entry处,从而实现上下文切换
static inline void stack_switch_call(void *sp, void *entry, void *arg) {
asm volatile(
#if __x86_64__
"mov %%rsp, %%r8;"
"mov %0, %%rsp;"
"push %%rbx;"
"push %%r8;"
"push %%rbp;"
"push %%r12;"
"push %%r13;"
"push %%r14;"
"push %%r15;"
"mov %%rsp, %%rbp;"
"sub $0x100, %%rsp;"
"mov %2, %%rdi;"
"call *%1"
:
: "c"((uintptr_t)sp - 8), "d"((uintptr_t)entry), "a"((uintptr_t)arg)
#else
"movl %%ecx, 4(%0); movl %0, %%esp; movl %2, 0(%0); call *%1"
:
: "b"((uintptr_t)sp - 8), "d"((uintptr_t)entry), "a"((uintptr_t)arg)
#endif
);
}
// 将call preserved registers的值恢复到切换上下文之前
static inline void restore_registers_call() {
asm volatile(
#if __x86_64__
"add $0x100, %%rsp;"
"pop %%r15;"
"pop %%r14;"
"pop %%r13;"
"pop %%r12;"
"pop %%rbp;"
"pop %%r8;"
"pop %%rbx;"
"mov %%r8, %%rsp;"
:
:
#else
"movl 4(%%esp), %%ecx"
:
:
#endif
);
}
调试 & 坑
调试信息打印函数:
为了方便调试,我们可以定义一个debug_printf函数,并利用宏的机制来开启或关闭该信息的显示。
#define DEBUG 0
// 调试打印函数
void debug_printf(const char *fmt, ...) {
if (DEBUG) {
va_list args;
va_start(args, fmt);
vprintf(fmt, args);
va_end(args);
}
}
GDB:
由于这个实验涉及到使用内联汇编代码实现上下文切换,掌握gdb按汇编指令单步运行,来查看stack_swicth_call与restore_registers_call前后,寄存器是否保存正确、栈是否对齐,就显得十分重要。
关于如何使用gdb调试,具体可以参考我的博客,里面几乎涵盖了这次实验会用到的所有gdb命令。
我碰到的坑:
-
堆栈没有对齐,报错SEGEFV;
-
画蛇添足,在co_wait里若发现协程状态为CO_DEAD就主动释放了该协程内存:
不要在co_wait中释放协程,在destructor中统一释放。
M3:系统调用 Profiler sperf
在这个实验中,我们需要实现命令行工具sperf:
sperf COMMAND [ARG]...
它会在系统中执行COMMAND命令,并为COMMAND传入ARG参数(列表),然后统计命令执行的系统调用所占的时间。
显示系统调用序列
根据实验说明,strace可以得到系统调用。它会 “重置” 某个进程的状态机,通过exceve使 “程序从头开始执行” 的系统调用。为了进一步使其显示相应调用的时间,我们可以使用-T参数,比如:
> strace -T ls .
execve("/usr/bin/ls", ["ls", "."], 0x7ffc449974d0 /* 36 vars */) = 0 <0.000147>
brk(NULL) = 0x557441898000 <0.000075>
arch_prctl(0x3001 /* ARCH_??? */, 0x7ffef498a610) = -1 EINVAL (Invalid argument) <0.000032>
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f4df563c000 <0.000031>
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) <0.000033>
# 省略很多行
newfstatat(1, "", {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x9), ...}, AT_EMPTY_PATH) = 0 <0.000030>
write(1, "Makefile sperf-64 sperf.c\n", 28Makefile sperf-64 sperf.c
) = 28 <0.000090>
close(1) = 0 <0.000032>
close(2) = 0 <0.000029>
exit_group(0) = ?
+++ exited with 0 +++
为了从strace的输出中提取到每个系统调用的名称和执行时间,我们可以使用正则表达式进行匹配。
实现sperf
根据实验说明,我们可以得到sperf程序的整体结构如下:
int main(int argc, char *argv[]) {
int fd[2];
if (pipe(fd) == -1) {
// 创建管道失败
}
int pid = fork();
if (pid == -1) {
// 子进程创建失败
}else if (pid == 0) {
// 子进程,执行strace命令
execve(...);
// 不应该执行此处代码,否则execve失败,出错处理
} else {
// 父进程,读取strace输出并统计
}
}
子进程:
对于子进程来说,只需要将管道写入端重定向到标准输出并且向execve传入正确的参数即可:
int main(int argc, char *argv[]) {
if (pid == -1) {
// 子进程创建失败
debug_printf("fork failed\n");
exit(EXIT_FAILURE);
} else if (pid == 0) {
// 关闭管道读取端,并将管道写入端重定向到标准输出
close(fd[0]);
if (dup2(fd[1], STDERR_FILENO) == -1) {
// 重定向失败
debug_printf("dup2 failed!\n");
close(fd[1]);
exit(EXIT_FAILURE);
}
// 执行strace
char *exec_argv[argc + 2];
exec_argv[0] = "strace";
exec_argv[1] = "-T";
for (int i = 1; i < argc; i++) {
exec_argv[i + 1] = argv[i];
}
exec_argv[argc + 1] = NULL;
char *exec_envp[] = {
"PATH=/bin",
NULL,
};
execve("strace", exec_argv, exec_envp);
execve("/bin/strace", exec_argv, exec_envp);
execve("/usr/bin/strace", exec_argv, exec_envp);
perror(argv[0]);
close(fd[1]);
exit(EXIT_FAILURE);
} else {
// 父进程,读取strace输出并统计
// ...
}
}
父进程:
对于父进程而言,除了使用正则表达式是从strace的输出提取所需信息之外,我们还要考虑如何存储这些信息。这里我使用的是链表,具体实现如下:
// 链表
typedef struct list_node {
char *name;
double time;
struct list_node *next;
} list_node;
// 链表插入节点,同时保证时间始终从大到小排序
list_node *insert_list_node(list_node *head, list_node *node) {
if (node == NULL) {
return head;
}
if (head == NULL || head->time < node->time) {
if (head != NULL) {
node->next = head;
}
return node;
}
list_node *prev = head;
for (list_node *curr = head->next; curr != NULL; curr = curr->next) {
if (curr->time < node->time) {
break;
}
prev = curr;
}
node->next = prev->next;
prev->next = node;
return head;
}
// 释放链表内存
void free_list(list_node *head) {
list_node *curr = head;
while (curr != NULL) {
list_node *next = curr->next;
if (curr->name != NULL) {
free(curr->name);
}
curr->name = NULL;
free(curr);
curr = next;
}
return;
}
有了这个链表之后,再去实现父进程的逻辑就比较简单了。
int main(int argc, char *argv[]) {
if (pid == -1) {
// 子进程创建失败
debug_printf("fork failed\n");
exit(EXIT_FAILURE);
} else if (pid == 0) {
// 子进程,执行strace
// ...
} else {
// 定义正则表达式
regex_t reg1, reg2;
if (regcomp(®1, "[^\\(\n\r\b\t]*\\(", REG_EXTENDED) ||
regcomp(®2, "<.*>", REG_EXTENDED)) {
debug_printf("regcomp failed!\n");
exit(EXIT_FAILURE);
}
// 链表记录各项调用时间信息
list_node *head = NULL;
// 调用总时间
double total_time = 0;
// 管道读取缓存
char buffer[BUFFER_SIZE];
// 关闭管道写入端,并从管道中读取数据
close(fd[1]);
FILE *fp = fdopen(fd[0], "r");
// 当前时间
int curr_time = 1;
// 运行标志
int run_flag = 1;
while (run_flag) {
while (fgets(buffer, BUFFER_SIZE, fp) > 0) {
// 读取到 +++ exited with 1/0 +++ 退出
if (strstr(buffer, "+++ exited with 0 +++") != NULL ||
strstr(buffer, "+++ exited with 1 +++") != NULL) {
run_flag = 0;
break;
}
// 使用正则表达式获取信息
regmatch_t regmat1, regmat2;
if (regexec(®1, buffer, 1, ®mat1, 0) ||
regexec(®2, buffer, 1, ®mat2, 0)) {
continue;
}
// 读取调用名称信息
int len = 0;
len = regmat1.rm_eo - regmat1.rm_so;
char *name = (char *)malloc(sizeof(char) * len);
strncpy(name, buffer + regmat1.rm_so, len);
name[len - 1] = '\0';
// 读取时间信息
len = regmat2.rm_eo - regmat2.rm_so - 2;
char *value = (char *)malloc(sizeof(char) * len);
strncpy(value, buffer + regmat2.rm_so + 1, len);
double spent_time = atof(value);
// 及时释放value内存
free(value);
value = NULL;
// 更新总时间
total_time += spent_time;
// 将信息保存到链表中
list_node *node = NULL;
int find_flag = 0;
list_node *prev = NULL;
for (list_node *curr = head; curr != NULL; curr = curr->next) {
// 若信息已存在,则将其更新后,重新插入
if (strcmp(curr->name, name) == 0) {
find_flag = 1;
if (prev == NULL) {
head = curr->next;
} else {
prev->next = curr->next;
}
node = curr;
// 信息存在,及时释放name内存
free(name);
name = NULL;
break;
}
prev = curr;
}
if (find_flag) {
// 更新信息
node->time += spent_time;
} else {
// 新建节点,初始化信息
node = (list_node *)malloc(sizeof(list_node));
node->name = name;
node->time = spent_time;
}
// 插入链表
head = insert_list_node(head, node);
}
// 格式化打印前五占比调用信息
printf("Time: %ds\n", curr_time);
int k = 0;
for (list_node *node = head; node != NULL; node = node->next) {
if (k++ >= PRINT_NUM) {
break;
}
printf("%s (%0.1f%%)\n", node->name, node->time / total_time * 100);
}
printf("=============\n");
curr_time += TIME_INTERVAL_SEC;
sleep(TIME_INTERVAL_SEC);
}
// 关闭管道读取端,释放相关资源
regfree(®1);
regfree(®2);
fclose(fp);
close(fd[0]);
free_list(head);
exit(EXIT_SUCCESS);
}
}
M4:C Real-Eval-Print-Loop crepl
M4要求我们实现一个类似Python Shell的“交互式Shell”程序crepl。具体来说,crepl逐行读取标准输入,根据内容进行处理:
- 如果输入的一行定义了一个函数,则把函数编译并加载到进程的地址空间中;
- 如果输入是一个表达式,则把它的值输出。
为了简化问题,实验还额外添加了两条限制:
- 函数总是以int开头,即:函数返回类型始终为int。
- 如果一行不是以int开头,我们就认为这一行是一个C语言的表达式。
这个实验也是比较有趣的一个,做完之后会对动态加载有更好的理解。
解释器
表达式wrapper:
每当我们收到一个表达式,例如:gcd(256, 144) 的时候,我们都可以 “人工生成” 一段 C 代码,即生成一个wrapper函数。
int main() {
static char line[4096];
while (1) {
printf("crepl> ");
fflush(stdout);
if (!fgets(line, sizeof(line), stdin)) {
break;
}
// 除去空白
actual_line = strip(line);
// 打开文件
FILE *fp = fopen("/tmp/a.c", "a+");
if (fp == NULL) {
fprintf(stderr, "fopen error: %s\n", strerror(errno));
exit(EXIT_FAILURE);
}
if (strncmp(actual_line, "int ", 4) == 0) {
// int开头为函数,函数直接写入文件,等待后续编译即可
fputs(actual_line, fp);
} else {
// 非函数(表达式),使用包装器写入文件,同样等待后续编译即可
is_expr = 1;
fprintf(fp, "int __expr_wrapper_%d() { return %s; }", expr_count++,
actual_line);
}
// 关闭文件
fclose(fp);
// ...
}
}
编译和加载:
为了增加实验难度,禁止使用C标准库system和popen函数。因此,我们使用类似M2中的方法,即fork配合exec family的系统调用,将传入的函数编译为共享库。其中,子进程负责编译;父进程根据传入内容,计算出输出结果。
int main() {
while(1) {
// 写入文件
// ...
int pid = fork();
if (pid == -1) {
// 子进程创建失败
fprintf(stderr, "fork error: %s\n", strerror(errno));
exit(EXIT_FAILURE);
} else if (pid == 0) {
// 子进程使用execve执行gcc
char *exec_argv[] = {
"gcc",
"-fPIC",
"-shared",
"/tmp/a.c",
"-o",
"liba.so",
NULL,
};
execve("/usr/bin/gcc", exec_argv, NULL);
// execve()仅执行失败返回
perror("execve");
exit(EXIT_FAILURE);
} else {
// 父进程等待子进程结束
int status;
if (waitpid(pid, &status, 0) == -1) {
fprintf(stderr, "waitpid error: %s\n", strerror(errno));
exit(EXIT_FAILURE);
}
if (WEXITSTATUS(status) != 0) {
// 子进程编译失败
printf("compile error\n");
continue;
}
// 如果是表达式,则需要加载库,并计算输出结果
if (is_expr) {
// 加载库
void *handle = dlopen("/tmp/liba.so", RTLD_LAZY);
if (handle == NULL) {
fprintf(stderr, "dlopen error: %s\n", dlerror());
exit(EXIT_FAILURE);
}
// 获取表达式wrapper名称
int expr_count_len = 0;
for (int i = expr_count; i > 0; i /= 10) {
expr_count_len++;
}
char expr_name[expr_prefix_len + expr_count_len];
sprintf(expr_name, "__expr_wrapper_%d", expr_count - 1);
// 获取表达式wrapper的函数指针
int (*func)() = dlsym(handle, expr_name);
if (func == NULL) {
fprintf(stderr, "dlsym error: %s\n", dlerror());
dlclose(handle);
exit(EXIT_FAILURE);
}
// 运行表达式wrapper
int result = func();
printf("%d\n", result);
// 关闭库
dlclose(handle);
// 重置is_expr
is_expr = 0;
} else {
// 定义函数成功
printf("ok\n");
}
}
}
}
坑:
这个实验整体来说比较简单,但我还是碰到一个坑,就是通过execve使用gcc时始终报错gcc: fatal error: cannot execute 'cc1': execvp: No such file or directory。起初,我判断是,execve函数的envp参数没设置对,补加了cc1所在的路径到环境变量PATH中去,但仍然报错。后续查阅资料,根据StackOverflow的这个帖子,又尝试了在gcc所在目录添加一个cc1的软链接,这时候报错信息变成了gcc: fatal error: '-fuse-linker-plugin', but liblto_plugin.so not found,仍然不能正常运行。最后我尝试了以下命令去重新安装gcc。
sudo apt-get update
sudo apt-get install --reinstall build-essential
在apt进行update的时候始终报错E: Release file for http://archive.ubuntu.com/ubuntu/dists/jammy-updates/InRelease is not valid yet (invalid for another 2h 54min 29s). Updates for this repository will not be applied.。查阅资料后,发现这是因为wsl的时间不正确,可以使用sudo hwclock --hctosys 命令进行校准。在校准后,再去重新安装gcc之后,问题就解决了。
M5:实现文件恢复工具 frecov
参考
M2: