
NJU-OS笔记
这篇博客流水线的记录一下自己学习NJU-OS的笔记。
1 操作系统概述
本课程讨论狭义的操作系统,即:对单一计算机硬件系统作出抽象、支撑程序执行的软件系统。
计算机历史
理解操作系统
理解操作系统,就是回答下面三个问题:
- 操作系统服务谁?
- 操作系统服务应用程序,而程序可以理解成状态机。
- 注:课程涉及多线程Linux应用程序。
- 站在应用视角,操作系统能为程序提供什么服务?
- 操作系统 = (可操作的)对象 + (可调用的)API
- 注:课程只涉及 POSIX + 部分Linux特性。
- 站在硬件视角,如何实现操作系统并提供这些服务?
- 操作系统 = C程序
- 注:课程涉及 xv6,并在此基础上实现一个迷你操作系统。
xv6 是MIT为操作系统的课程,开发的一个教学目的的操作系统。
2 操作系统上的程序
什么是程序
操作系统中的一般程序
课后作业中,使用tmux实现多窗口管理这一项让我收获挺多的,具体参见我的tmux笔记。此外,还有一些WSL环境,终端个性化配置,Vim快捷键以及gdb调试等等小项目,也非常有意义。
3 多处理器编程
并发
并发的基本单位——线程:
共享内存的多个执行流:
- 执行流拥有独立的堆栈/寄存器
- 共享全部的内存(指针可以相互引用)
POSIX Threads
实现原子性
实现临界区之间的绝对串行化 程序其他部分依然并行执行
4 理解并发程序执行
5 并发控制:互斥
共享内存的互斥
自旋锁 Spinlock
自旋锁是一种基于忙等待的锁。
当一个线程需要获取自旋锁时,如果锁已经被占用,那么这个线程会一直忙等待,直到锁被释放。自旋锁的实现通常是基于原子操作的方式,当一个线程获取锁时,它会使用原子操作来修改锁的状态,以避免并发访问锁时的数据竞争问题。
x86 LOCK指令前缀:
x86的LOCK指令前缀是用于多处理器环境下实现原子操作(atomic operation)的机制。
使用带LOCK前缀的指令能实现多种原子操作,如:
- 原子交换:例如在实现Spinlock中的锁获取和释放操作时,可以使用XCHG指令和LOCK前缀来保证锁的原子性。
- 原子比较-交换:例如在实现无锁算法中,可以使用CMPXCHG指令和LOCK前缀来实现原子比较-交换操作。
实现自旋锁:
// atomic exchange
int xchg(volatile int *addr, int newval) {
int result;
asm volatile ("lock xchg %0, %1"
: "+m"(*addr), "=a"(result) : "1"(newval));
return result;
}
int locked = 0;
void lock() { while (xchg(&locked, 1)) ; }
void unlock() { xchg(&locked, 0); }
原子操作与Bus Lock:
早期原子操作的实现依靠总线上锁来实现。具体如下,当一个处理器执行带有LOCK前缀的指令时,它会锁住内存总线,防止其他处理器同时对同一内存地址进行操作,从而确保了原子操作的正确性。
原子操作的现代实现:
现代处理器中,原子操作通常是通过硬件支持来实现的,它们能够保证对内存的原子操作,而不需要锁住总线或者使用其他的软件实现方式,从而提高了系统的性能和并发能力。
C++支持的原子操作:
详细信息可以阅读cppreference。
自旋锁的缺陷:
- 自旋 (共享变量) 会触发处理器间的缓存同步,延迟增加;
- 除了进入临界区的线程,其他处理器上的线程都在空转,且争抢锁的处理器越多,利用率越低;
- 获得自旋锁的线程可能被操作系统切换出去。
自旋锁适合的使用场景:
- 临界区几乎不 “拥堵”;
- 持有自旋锁时禁止执行流切换。
换句话说,自旋锁适用于短临界区的场景,比如操作系统内核的并发数据结构。
互斥锁 Mutex
互斥锁(mutex)是一种基于操作系统的同步原语,它使用了操作系统提供的系统调用来实现线程同步和互斥。
互斥锁的实现通常是基于一种叫做“睡眠-唤醒”机制的方式,当一个线程需要获取锁时,如果锁已经被占用,那么这个线程会被阻塞,直到锁被释放。当锁被释放时,操作系统会唤醒等待的线程,让它们竞争锁。
快速用户空间互斥锁 Futex
Futex(Fast Userspace Mutex)是一种基于用户空间的同步原语。实际上,就是Spinlock和Mutex的混合。
Futex的上锁过程:
- 先在用户空间自旋。
- 如果获得锁,直接进入;
- 未能获得锁,系统调用。
- 解锁以后也需要系统调用。
5 总结
软件不够,硬件来凑 (自旋锁) 用户不够,内核来凑 (互斥锁)
6 并发控制:同步
线程同步
线程同步:在某个时间点共同达到互相已知的状态。
条件变量
条件变量是一种用于线程间通信的同步原语,它允许一个线程等待另一个线程满足特定条件后再继续执行。
条件变量通常需要和互斥锁一起使用,以避免出现竞争和冲突。当一个线程需要等待特定条件时,它会释放互斥锁并进入等待状态,直到另一个线程满足条件并唤醒它。
信号量
信号量是一种计数器,用于控制同时可以访问共享资源的线程或进程数量。
在多个线程或进程竞争同一资源的情况下,信号量可以限制同时访问资源的线程或进程数量,避免竞争和冲突。
信号量有两种类型:二元信号量和计数信号量。
- 二元信号量只有两种状态,0和1,用于实现互斥锁的功能;
- 计数信号量可以有多个状态,用于实现多个线程或进程之间的协作和同步。
值得注意的是,虽然C++标准库中没有直接提供信号量的实现,但可以通过第三方库或者自己编写代码(互斥量+原子操作)来实现信号量。
7 真实世界的并发编程
并发编程的真实应用场景:
- 高性能计算 (注重任务分解): 生产者-消费者 (MPI/OpenMP)
- 数据中心 (注重系统调用): 线程-协程 (Goroutine)
- 人机交互 (注重易用性): 事件-流图 (Promise)
8 并发Bug和应对
死锁 Dead Lock
死锁产生的条件:
- 互斥:一个资源每次只能被一个进程使用
- 请求与保持:一个进程请求资阻塞时,不释放已获得的资源
- 不剥夺:进程已获得的资源不能强行剥夺
- 循环等待:若干进程之间形成头尾相接的循环等待资源关系
数据竞争 Data Race
数据竞争(data race)是指多个线程同时对共享数据进行读写操作,而导致数据出错或不稳定结果的情况。
用互斥锁保护好共享数据,从而消灭一切数据竞争。
9 操作系统的状态机模型
硬件和软件的桥梁
计算机启动的流程:
为了让计算机能运行任何我们的程序,一定存在软件/硬件的约定。
比如,CPU reset 后,处理器处于某个确定的状态。其中,PC 指针一般指向一段存储了厂商提供的 firmware (固件) 的memory-mapped ROM。
ROM(Read Only Memory)只读存储器和RAM(Random Access Memory)随机存储器是计算机中两种非常重要的内存。
其中,ROM一旦烧录后无法更改,且一般存储在专用芯片中,如BIOS ROM直接焊在主板上,一些外设也有自己的ROM。而RAM则可以支持读写,一般被称为内存条。
当计算机启动从firmware开始执行后,它将提供一种机制将用户数据载入内存。
以Legacy BIOS为例,计算机的启动流程是:
- 启动ROM中保存的启动固件BIOS,并且初始化各种硬件。
- BIOS首先搜索所有可引导设备,包括硬盘、U盘等,找到第一个可引导设备(通常是硬盘)。
- BIOS读取该可引导设备的第一个扇区MBR,将其写入到物理内存0x7c00位置。
- 最后,BIOS跳转到0x7c00开始执行MBR中代码,由MBR加载第二阶段引导程序boot loader。
- boot loader加载操作系统内核,完成计算机启动。
主引导记录MBR(Master Boot Record)存储在硬盘的第1个扇区。它包含一个很小的引导程序,可以加载第二阶段引导程序,并由第二阶段引导程序负责加载操作系统内核,完成计算机启动。
启动总结:
总的来说,计算机不管使用哪种技术启动,无外乎三个步骤:
- ROM Stage:
- 初始化基本的CPU和外设。
- 初始化DRAM,提供最基本的内存功能。
- 将固件更多的代码加载到DRAM中。
- RAM Stage:
- 初始化更多的内存功能和外设。
- 找到可引导启动的介质,如硬盘。
- Find Something to boot Stage:
- 检测所有外接设备,例如USB、SD卡、硬盘等。
- 在被 detecting 的设备中查找一个包含引导程序的设备。
- 读取其引导扇区,将其加载到内存中。
值得注意的是,在ROM stage期间,任务通常都需要很底层的机器代码来直接操纵CPU和设备寄存器。
这是因为没有内存,没有C语言运行需要的栈空间,所以开始往往是汇编语言,直接在ROM空间上运行。直到在找到个临时空间(Cache空间用作RAM,Cache As Ram, CAR)后,C语言终于可以粉墨登场了,后期用C语言初始化内存和为这个目的需要做的一切服务。
固件 firmware:
固件是一种存储在只读内存(ROM)中的软件。它担任着实现一个数码产品最基础、最底层功能。比如,计算机主板上的基本输入/输出系统BIOS就是一种固件。
BIOS vs UEFI:
详情查看这篇博客。
计算机软件层次:
硬件 -> 固件 -> 操作系统 -> 驱动程序 -> 应用软件
- 硬件:计算机的各种物理组件,如 CPU、内存、显卡等。
- 固件:存储在只读内存中的低层软件,用于控制硬件。如BIOS。
- 操作系统:建立在固件之上,管理和调度硬件资源。
- 驱动程序:运行在操作系统之上,管理不同硬件与操作系统交互。
- 应用软件:运行在操作系统提供的环境上,实现实际功能。
操作系统的状态机模型
Firmware 和 boot loader 共同完成 “操作系统的加载”
10 状态机模型的应用
查看状态机执行
gdb 的隐藏功能
- record full - 开始记录
- record stop - 结束记录
- reverse-step/reverse-stepi - “时间旅行调试”
采样状态机执行
Profiler 和性能摘要:
隔一段时间 “暂停” 程序、观察状态机的执行
- 中断就可以做到
- 将状态“记账”
- 执行的语句
- 函数调用栈
- 服务的请求
- 得到统计意义的性能摘要
Model Checker/Verifier
模型检验(Model Checking)是一个自动化的算法,用于验证一个抽象模型是否满足特定的性质。
模型检验器(Model Checker)即是使用该算法实现的一个工具。
11 操作系统上的进程
回顾
定制Linux:
BusyBox: The Swiss Army Knife of embedded Linux
adb shell(toybox)
Linux操作系统启动流程:
- CPU Reset
- Firmware
- Loader
- Kernel_start
- /bin/init
- 程序执行+系统调用
应用视角的操作系统:
操作系统为所有程序提供API
- 进程&线程(状态机)管理
- fork,execve,exit - 进程的创建、改变和删除
- pthread_create,pthread_join,pthread_exit - 线程的创建和退出
- 存储(地址空间)管理
- mmap - 虚拟地址空间管理
- 文件(数据对象)管理
- open,close,read,write - 文件访问管理
- mkdir,link,unlink - 目录管理
fork()
理解操作系统是状态机管理者:
- 操作系统在物理内存中保存多个状态机;
- 通过虚拟内存实现,拿一个来执行;
- 中断后进入操作系统代码,换一个执行。
状态机管理之创建状态机:
UNIX的答案是fork,即:做一份状态机的完整复制(内存、寄存器现场)。
理解fork函数:
pid_t fork(void)
在fork函数返回后,会有两个进程同时运行,其中一个是父进程,另一个是新创建的子进程。
在子进程创建成功后,它会复制父进程的代码和数据段,并且开始执行从fork函数返回的位置。也就是说,子进程会从fork函数返回的地方开始执行,而不是从程序的起始位置开始执行。
需要注意的是,在子进程中,fork函数的返回值是0,而在父进程中,fork函数的返回值是新创建的子进程的进程ID。因此,在父进程中可以通过判断fork函数的返回值来区分当前进程是父进程还是子进程。
execve()
状态机管理之替换状态机:
UNIX的答案是execve,即:将当前运行的状态机重置成另一个程序的初始状态。
理解execve函数:
int execve(const char *pathname, char *const argv[], char *const envp[]);
- pathname:指定要执行的程序的路径,可以是绝对路径或者相对路径。如果路径中不包含目录分隔符 /,则会从环境变量 PATH 中查找可执行文件。
- argv:一个以 NULL 结尾的字符串数组,用于指定新程序的命令行参数。第一个元素通常是程序的名称,后面的元素是程序的参数。注意,第一个元素是程序的名称,而非路径名。
- envp:一个以 NULL 结尾的字符串数组,用于指定新程序的环境变量。每个字符串都是一个形如 key=value 的键值对,表示一个环境变量的值。
execve函数执行成功时,不会返回到调用进程,而是直接将当前进程替换为新程序的进程。如果执行失败,则会返回 -1,并设置相应的错误码。
12 进程的地址空间
进程地址空间的组成:
- 代码段(text segment):存放可执行文件的指令,也称为二进制代码或可执行代码。
- 数据段(data segment):存放程序中已经初始化的全局变量和静态变量。
- BSS段(bss segment):存放程序中未初始化的全局变量和静态变量,通常用0来填充。
- 堆(heap):用于动态分配内存,例如使用C/C++中的malloc()函数或是C++中的new运算符申请内存。
- 栈(stack):用于存放函数的局部变量、函数的参数以及函数调用时的返回地址等。
- 其他:还有一些用于存放动态链接库、共享内存、内存映射文件等的内存区域。
进程的地址空间管理
- 进程的地址空间 = 内存里若干连续的 “段”
- 每一段是可访问 (读/写/执行) 的内存
- 可能映射到某个文件和/或在进程间共享
管理进程地址空间的系统调用:
// 映射
void *mmap(void *addr, size_t length, int prot, int flags,
int fd, off_t offset);
// 取消映射
int munmap(void *addr, size_t length);
内存映射一致性:
操作系统通过内存管理单元(MMU)来保证内存映射的一致性。MMU是一种硬件设备,用于将虚拟地址转换为物理地址,并执行访问权限控制。
当进程访问内存时,操作系统会将虚拟地址转换为物理地址,然后访问对应的物理地址。这个过程是由MMU完成的。MMU会通过页表或段表来进行地址转换,这些表会将虚拟地址映射到物理地址,并记录每个内存页或段的权限信息,例如读、写、执行等。
此外,操作系统还会使用一些技术来提高内存映射的一致性。例如,使用缓存(cache)来加速内存访问,并使用缓存一致性协议来确保多个缓存之间的数据一致性;使用TLB(Translation Lookaside Buffer)来缓存页表或段表的部分内容,加速地址转换。这些技术可以提高内存访问的效率,同时保证内存映射的一致性。
地址空间的作用
实现进程隔离:
实现了操作系统最重要的功能:进程之间的隔离。
代码注入:
我们可以改内存,也可以改代码!
13 系统调用和UNIX Shell
Shell
简介:
Shell 是一种计算机程序,它将操作系统的服务暴露给人类用户或其他程序。
一般来说,操作系统的 Shell 使用命令行界面(CLI,Command Line Interface)或图形用户界面(GUI,Graphics User Interface),具体取决于计算机的角色和特定操作。
Shell Programming Language是一门把用户指令翻译成系统调用的编程语言。
Shell Scripts 是由 Shell Programming Language 编写的脚本文件,它们通常以 .sh 扩展名结尾,包含一系列的 Shell 命令和脚本语句,用于执行特定的操作和任务。
功能:
- 重定向: cmd > file < file 2> /dev/null
- 顺序结构: cmd1; cmd2, cmd1 && cmd2, cmd1 || cmd2
- 管道: cmd1 | cmd2
- 预处理: $(), <()
- 变量/环境变量、控制流……
未来展望:
- fish、zsh等用户友好、易用且美观的命令行界面
- tldr、thefuck等自动补全工具
- 类似vscode的命令板块(Ctrl-Shift-P)
- Executable Formal Semantics for the POSIX Shell
终端和Job Control
终端:
终端(Terminal)是一种计算机的输入/输出设备,用于与计算机进行交互,输入指令或命令,输出结果或信息。
在早期的计算机系统中,终端通常是一个物理设备,例如打字机或显示器。用户可以通过终端连接到计算机,并通过终端输入指令或命令,操作计算机。
在现代操作系统中,终端通常是软件模拟的。例如,在Unix或Linux系统中,终端通常是一个命令行界面,用户可以通过终端窗口输入命令,并在终端窗口中看到计算机的响应。
终端与Shell:
终端和shell是计算机系统中密切相关的两个概念,它们之间有着紧密的关系。
当用户在终端中输入命令时,终端会将用户输入的内容传递给Shell,由Shell对其进行解释和执行,并将结果输出到终端中。
Session & Process Group:
会话是一组相互关联的进程的集合。
在一个会话中,每个进程组都有一个唯一的进程组ID(PGID),并且每个进程都会属于一个进程组。进程可以通过setpgid系统调用来将自己或其他进程加入到指定的进程组中,也可以通过getpgid系统调用来获取自己或其他进程所在的进程组ID。
进程组和会话之间的关系如下:
- 一个会话可以包含多个进程组。
- 每个进程组可以包含多个进程。
- 一个进程组可以与一个控制终端关联,也可以从控制终端中分离出来。

Job Control:
The PGID (process-group ID) is preserved across an execve(2) and inherited in fork(2)…
Each process group is a member of a session.

A session can have a controlling terminal.
- At any time, one (and only one) of the process groups in the session can be the foreground process group for the terminal; the remaining process groups are in the background.
- If a signal is generated from the terminal (e.g., typing the interrupt key to generate SIGINT), that signal is sent to the foreground process group.
- Only the foreground process group may read(2) from the terminal; if a background process group tries to read(2) from the terminal, then the group is sent a SIGTTIN signal, which suspends it.
14 C标准库的实现
libc
libc是一个C语言标准库,它包括大量的函数和头文件,提供了许多常用的系统调用和库函数,用于编写Unix和类Unix操作系统中的应用程序。
libc是操作系统中最基本的库之一,它为其他库和应用程序提供了基础的支持。
为什么需要libc:
libc提供一层基础的封装,使得开发人员更方便了。
在C语言标准中,有两种环境:hosted和freestanding。Hosted环境是指在操作系统上使用标准库的环境,这种环境下程序可以使用标准库提供的函数和语言特性。而Freestanding环境则是指在没有操作系统或标准库支持的情况下运行的环境,这种环境下程序必须自行处理底层硬件和系统资源。
libc组成
封装1:存粹的计算:
- string.h: 字符串/数组操作
- stdlib.h:atoi, atol, atoll, strtoull, rand
- setjmp.h: 实现跨栈的非局部跳转
- math.h: …
封装2:文件描述符:
以stdio.h为例,封装了FILE*和vprintf系列
封装3:更多进程/操作系统功能:
封装4:地址空间:
malloc 和 free
实现malloc:
15 a fork() in the road
fork()行为的补充
- fork 状态机复制包括持有的所有操作系统对象
- execve “重置” 状态机,但继承持有的所有操作系统对象
文件描述符:一个指向操作系统内对象的 “指针”
- 从 0 开始编号 (0, 1, 2 分别是 stdin, stdout, stderr)
- 可以通过 open 取得;close 释放;dup “复制”
- 对于数据文件,文件描述符会 “记住” 上次访问文件的位置
- 也就是说,操作系统必须正确管理文件的偏移量
值得注意的是,dup() 的两个文件描述符是共享偏移量的。因此,dup() 返回的新文件描述符和原文件描述符共享同一个文件偏移量,它们对文件读写操作是相互影响的。
A fork() in the road
fork()是UNIX时代的遗产:
fork + execve:如果只有内存和文件描述符,这是十分优雅的方案
但在操作系统的演化过程中,为进程增加了更多的东西,比如:信号、线程等
16 可执行文件
状态机的描述:
操作系统的诞生就是为了给应用程序提供执行环境,而可执行文件就是最重要的操作系统对象!
可执行文件是一个描述了状态机的初始状态 + 迁移的数据结构,包括:
- 寄存器:大部分由 ABI 规定,操作系统负责设置,例如初始的 PC;
- 地址空间:二进制文件 + ABI 共同决定,例如 argv 和 envp (和其他信息) 的存储;
- 其他有用的信息 (例如便于调试和 core dump 的信息)。
可执行的条件:
- 具有执行的权限;
- 可以使用
chmod +x [file names]为文件增添可执行权限。
- 可以使用
- 加载器能识别的可执行文件。
常见的可执行文件:
Windows:
- EXE
- UEFI(Unified Extensible Firmware Interface)
- PE(Portable Executable)
UNIX/Linux:
- ELF(Executable Linkable Format)
解析可执行文件
GNU Binutils:
Binutils是一组开源工具集,用于创建、操作和转换二进制文件。可以按功能将Binutils分成两大部分,分别是
- 帮助生成可执行文件的工具,比如:ld (linker), as (assembler), ar (archiver);
- 帮助分析可执行文件的工具,比如:objcopy/objdump/readelf。
编译和链接
编译器生成文本汇编代码 → 汇编器生成二进制指令序列。
重定位 Relocation:
重定位是指将一个程序或库加载到内存中时,将它们在内存中的位置从编译时指定的地址(静态地址)调整为运行时实际的地址的过程。
重定位通常是由操作系统的动态链接器或加载器完成的,它们负责将程序或库加载到内存中,并修复程序或库中的所有引用,以便在运行时正确地执行。
ELF文件:
ELF 就是一个 “容器数据结构”,包含了必要的信息。
重新理解编译、链接流程:
编译器 (gcc):High-level semantics (C 状态机) → low-level semantics (汇编)
汇编器 (as):Low-level semantics → Binary semantics (状态机容器)
- “一一对应” 地翻译成二进制代码
- sections, symbols, debug info
- 不能决定的要留下 “之后怎么办” 的信息
- relocations
链接器 (ld):合并所有容器,得到 “一个完整的状态机”
- ldscript (-Wl,–verbose); 和 C Runtime Objects (CRT) 链接
- missing/duplicate symbol 会出错
17 可执行文件的加载
静态ELF加载器
加载器的功能:
- 解析数据结构 + 复制到内存 + 跳转;
- 创建进程运行时初始状态 (argv, envp, …)。
引导区加载程序 Boot Block Loader:
Boot Block Loader也是也一个加载器,它能加载操作系统内核。此外,Boot Block Loader通常也称为引导扇区(boot sector),它的大小则一般为512字节。
具体来说,Boot Block Loader加载操作系统的工作流程是:
- 首先,BIOS在启动盘第一个扇区,中查找引导程序,即:Boot Block Loader;
- 接着,BIOS会将该扇区中的512字节加载到内存中的0x7C00地址,并跳转到这个地址开始执行Boot Block Loader中的代码;
- 最后,由Boot Block Loader加载操作系统内核,并跳转到核心代码入口开始执行操作系统。
动态链接
拆解应用程序的必要性:
随着库函数越来越大,希望项目能够 “运行时链接”。
动态链接能够减少库函数的磁盘和内存拷贝,如果每个可执行文件里都有所有库函数的拷贝那也太浪费了。
18 x86代码导读
xv6是一个基于Unix V6操作系统的教学性质的操作系统,旨在帮助学生更好地理解操作系统的设计和实现。
19 实现上下文切换
20 处理器调度
动态优先级
21 操作系统设计
22 存储设备原理
持久存储介质:
- 构成一切文件的基础
- 逻辑上是一个 bit/byte array
- 根据局部性原理,允许我们按 “大块” 读写
- 评价方法:价格、容量、速度、可靠性
存储介质:磁
磁盘 Hard Disk:
通过在二维平面上放置许多磁带实现了1D → 2.5D (2D x n)。
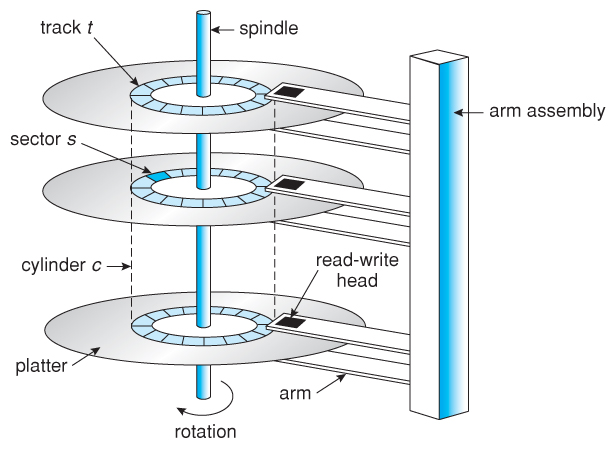
特点:
- 价格低:密度越高,成本越低;
- 容量高:因为平面上可以有数万个磁道;
- 读写速度:顺序读取速度较高,但随机读取速度比较勉强;
- 可靠性一般:存在机械部件,磁头划伤盘片导致数据损坏。
今天的应用场景:计算机系统的主力数据存储 (海量数据:便宜才是王道)
读取硬盘某个扇区的流程:
- 读写头需要到对应的磁道;
- 转轴将盘片旋转到读写头的位置。
通过缓存/调度等策略优化读取:
- 例如著名的 “电梯” 调度算法;
- 现代 HDD 都有很好的 firmware 管理磁盘 I/O 调度。
软盘 Floppy Disk:
把读写头和盘片分开——实现数据移动(计算机上的软盘驱动器 (drive) + 可移动的盘片)
特点:
- 价格低
- 容量低
- 读写速度:顺序和随机读取速度均较低
- 可靠性也较低
今天的应用场景:躺在博物馆供人参观
存储介质:坑
光盘 Compact Disk:
特点:
- 价格很低
- 容量高
- 读写速度:顺序读取速度高,但随机读取速度比较勉强,此外写入速度极低
- 可靠性高
存储介质:电
固态硬盘 Solid State Drive:
特点:
- 价格低
- 容量高
- 读写速度高
- 可靠性高
但它有一个致命的缺点,放电做不到 100% 放干净。因此,可能会出现数据丢失或存储介质失效的情况,也被称为NAND Wear-Out。
NAND Flash的全称是“Negative-AND Flash”,即“负与门闪存”。
NAND Wear-Out解决方案:软件定义磁盘
FTL(Flash Translation Layer)是一种在 NAND Flash 存储器上运行的软件层,用于管理和控制 NAND Flash 存储器中的数据读写和存储。
其中,Wear Leveling 是 FTL 技术中的一种重要技术,它通过软件管理 NAND Flash 存储器中的块,避免重复写入同一块,从而平衡存储介质中每个块的使用次数,延长 NAND Flash 存储器的使用寿命。
23 输入输出设备
总线、中断控制器和 DMA
总线 Bus:一个特殊的 I/O 设备
提供设备的注册和地址到设备的转发
中断控制器 Interrupt Controller:
GPU和异构计算
现代GPU:一个通用计算设备:
一个完整的众核多处理器系统
- 注重大量并行相似的任务
- 程序使用例如 OpenGL, CUDA, OpenCL, … 书写
- 程序保存在内存 (显存) 中
- nvcc (LLVM) 分两个部分
- main 编译/链接成本地可执行的 ELF
- kernel 编译成 GPU 指令 (送给驱动)
- nvcc (LLVM) 分两个部分
- 数据也保存在内存 (显存) 中
- 可以输出到视频接口 (DP, HDMI, …)
- 也可以通过 DMA 传回系统内存
24 设备驱动程序
设备驱动程序的原理
I/O设备的抽象:
I/O 设备的主要功能:能够读 (read) 写 (write) 的字节序列 (流或数组)
操作系统:设备 = 支持各类操作的对象 (文件)
- read - 从设备某个指定的位置读出数据
- write - 向设备某个指定位置写入数据
- ioctl(Input/Output Control)- 读取/设置设备的状态
因此,设备驱动就是把 read/write/ioctl 等系统调用翻译成设备听得懂的协议。
Linux设备驱动程序
Linux驱动一般是以内核模块的形式存在。
内核模块:一段可以被内核动态加载执行的代码
总结:
- 设备驱动将操作系统给上层应用提供的文件操作(read/write/ioctl)翻译成设备控制协议。
- 因为驱动是内核模块,所以设备在内核中初始化和注册。
- 换句话说,系统调用直接以函数调用的方式执行驱动代码。
GPU编程
存储设备的抽象
25 文件系统API
文件系统的作用
文件系统的设计目标:
- 提供合理的 API 使多个应用程序能共享数据
- 提供一定的隔离,使恶意/出错程序的伤害不能任意扩大
一句话总结,文件系统能够实现存储设备的虚拟化。
目录树:将虚拟磁盘 (文件) 组织形成的层次结构
树总得有个根结点
- 对于Windows来说,每个设备(驱动器)是一棵树。
- 其中,A:\ 和 B:\ 是早期操作系统中用来表示软盘驱动器。
- 对于其他设备,例如硬盘驱动器、光盘驱动器、USB 存储器等,它们通常被分配更高的卷标,例如 C:\、D:\ 等。
- 对于UNIX/Linux来说,它们只有一个根/,其他目录都是以/为起点。
Linux上的设备基本上都是在/dev目录下,那为什么还要额外挂载到其他目录呢?
/dev目录下的设备节点只提供了访问该设备的接口,但是若要访问设备上的文件系统,还需要使用mount命令将其"注入"到Linux的目录树中。
目录树的拼接:
UNIX: 允许任意目录 “挂载 (mount)” 一个设备代表的目录树
挂载(mounting)是指由操作系统使一个存储设备(诸如硬盘、CD-ROM或共享资源)上的计算机文件和目录可供用户通过计算机的文件系统访问的一个过程。
换句话说,挂载指的就是将设备文件中的顶级目录连接到主机中根目录下的某一目录,进而达成访问此目录就等同于访问设备文件的目的。
int mount(const char *source, const char *target,
const char *filesystemtype, unsigned long mountflags,
const void *data);
Linux实现文件挂载:
- 创建挂载点目录
- 使用 mount 命令直接将设备挂载到该目录
- 使用 umount 命令卸载设备
某些时候,操作系统会使用回环设备帮助实现挂载。
回环设备(loopback device)是Linux内核中一种特殊的设备,它允许将一个普通文件映射为一个块设备,从而可以在该文件上运行文件系统,就像运行在硬盘上一样。
mount命令背后是Linux虚拟文件系统(VFS)机制的工作,它提供了一个统一的接口,使得主机文件系统能够访问到多种不同文件系统。
Filesystem Hierarchy Standard (FHS):
Filesystem Hierarchy Standard (FHS) 是一个定义了 Linux 和其他类 Unix 操作系统下的文件系统组织结构标准的规范
- /usr:用于存放系统级别的应用程序和相关文件。
- /var:用于存放系统运行时的可变数据,如日志文件、缓存文件等。
- /bin:包含一些必要的系统工具和命令。
- /sbin:包含一些系统级别的管理工具和命令,只有管理员才有访问权限。
- /lib:包含一些系统级别的库文件,供应用程序使用。
- /etc:包含一些系统级别的配置文件。
- /dev:包含一些设备文件,用于访问硬件设备。
- /proc:包含一些进程相关的信息,可以动态访问。
目录API
目录管理:
- 创建 mkdir:创建一个目录
- 删除 rmdir:删除一个空目录
- 遍历 getdents:返回 count 个目录项 (ls, find, tree 都使用这个)
硬链接 hard link:允许一个文件被多个目录引用
软链接 symbolic link:类似 “快捷方式”
文件API
文件描述符:进程访问文件 (操作系统对象) 的 “指针”
- 通过 open/pipe 获得
- 通过 close 释放
- 通过 dup/dup2 复制
- fork 时继承
偏移量管理:
文件的读写自带 “游标”,这样就不用每次都指定文件读/写到哪里了
- open 时,获得一个独立的 offset
- dup 时,两个文件描述符共享 offset
- fork 时,父子进程共享 offset
- execve 时文件描述符不变
26 FAT和UNIX文件系统
文件系统的实现
想要实现文件系统,就是在一个 I/O 设备 (block device) 上实现所有文件系统 API,即:将磁盘虚拟化。
因此,文件系统就是一个数据结构。
文件系统的假设:按块访问
File Allocation Table (FAT)
File Allocation Table (FAT)是最早的磁盘文件系统之一。
研发背景:只需要支持相当小的文件
- 树状的目录结构
- 系统中以小文件为主 (几个 block 以内)
因此,采用链表的方式存储。
两种链表存储的设计:
- 在每个数据块后放置指针
- 优点:实现简单、无须单独开辟存储空间
- 缺点:单纯的 lseek 需要读整块数据
- 将指针集中存放在文件系统的某个区域
- 优点:局部性好;lseek 更快
- 缺点:集中存放的数据损坏将导致数据丢失
FAT细节:
ext2/UNIX文件系统
按对象方式集中存储文件/目录元数据
- 增强局部性 (更易于缓存)
- 支持链接
为大小文件区分 fast/slow path
- 小的时候应该用数组
- 连链表遍历都省了
- 大的时候应该用树 (B-Tree; Radix-Tree; …)
- 快速的随机访问
ext2 inode:
27 持久数据的可靠性
Redundant Array of Inexpensive Disks (RAID)
把多个 (不可靠的) 磁盘虚拟成一块非常可靠且性能极高的虚拟磁盘。
File System Checking
崩溃一致性: