
从GFS论文了解分布式文件系统
这篇博客主要记录我阅读分布式文件系统开山之作GFS的一些笔记。
- Target & Background
- Design Overview
- System Interactions
- Master Operation
- Fault Tolerance And Diagnosis
- Summary
- References
Target & Background
我们必须要注意一个系统的设计背景和目标,是因为一个系统通常是针对于某一个具体的应用领域而设计的。和语言一样,一个系统并不能做到样样精通,我们需要理解设计背后的trade-off。
Target:
高性能,可伸缩性,可靠性和可用性
Background:
在GFS论文中,作指出 分布式文件系统的四个背景:
- 组件故障是正常现象,而不是例外情况;
- 需要处理的文件通常都很大,而不是小文件;
- 大多数文件是通过在末尾追加新数据,而不是覆盖现有数据来进行改变的;
- 应该协同设计应用程序和文件系统,使得整个系统的灵活性更好.
Design Overview
Interface
GFS 作为一个分布式文件系统,对外提供了一个传统的单机文件系统接口。但是出于效率和使用性的角度,并没有实现标准的文件系统 POSIX API。
POSIX,Portable Operating System Interface,即可移植操作系统接口,其为 UNIX 系统的一个设计标准,很多类 UNIX 系统也在支持兼容这个标准,如 Linux。Windows 则部分支持此协议。
GFS提供了一个熟悉的文件系统接口,具有创建,删除,打开,关闭,读取和写入文件的常规操作,此外,GFS具有快照和记录附加操作。
Architecture
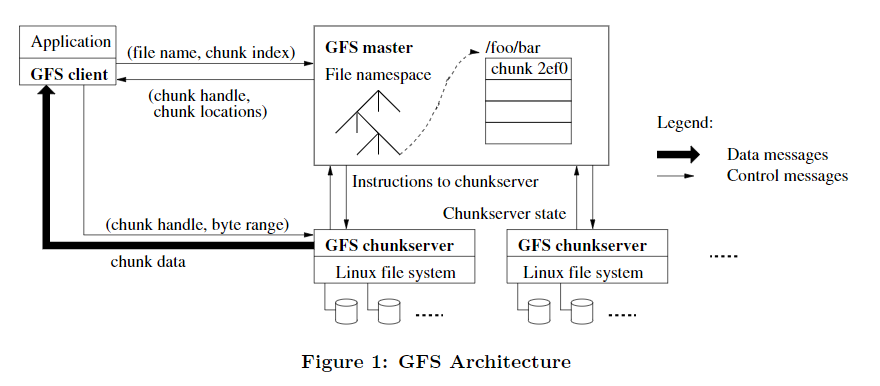
GFS的特点如下:
- 一个GFS集群由一个 master和多个 chunkservers 组成,并且可以由多个 clients 访问。
- 文件分为固定大小的块,且为了提高可靠性,每个块都复制到多个chunk server上。
- Master维护所有文件系统元数据。
- GFS客户端代码实现文件系统API,并与Master和chunk server通信以代表该应用程序读取或写入数据。
Single Master
Client 读数据的流程:
- GFS Client 首先对要读取的字节相对偏移量在 chunk size 固定的背景下计算出 chunk index;
- 给 GFS Master 发送 file name 以及 chunk index,即文件名和块序号;
- GFS Master 接收到查询请求后,将 filename 以及 chunk index 映射为 chunk handle 以及 chunk locations,并返回给 GFS Client;
- GFS Client 接收到响应后以 key 为 file name + chunk index,value 为 chunk handle + chunk locations 的键值对形式缓存此次查询信息;
- 接着,GFS Client 向其中一个 replicas (最有可能是最近的副本)发送请求,去请求中指定 chunk handle 以及块中的字节范围;
Chunk
GFS将文件分成 64MB 的固定块存储。
Chunk Size:
将文件分块存储,以达到可以并行处理的思想很好理解。但和典型的文件系统相比,GFS 的 Chunk Size 大得多。
例如,对于 64 位的 Linux 操作系统来说,其内存分配单元为 8kB,对于 32 位的 Linux 操作系统来说,内存分配单元为 4 kB。对于 SQL 服务器而言,通常的一次 I/O 磁盘读取则是 8KB(俗称 IO Chunk Size)。
采用大Chunk Size的原因如下:
- 首先,它减少了 Client 与 Master 服务器交互的次数,因为对同一块进行多次读写仅仅需要向 Master 服务器发出一次初始请求,就能获取全部的块位置信息。这可以有效地减少 Master 的工作负载;
- 其次,减少了 GFS Client 与 GFS chunkserver 进行交互的数据开销,这是因为数据的读取具有连续读取的倾向,即读到 offset 的字节数据后,下一次读取有较大的概率读紧挨着 offset 数据的后续数据,chunk 的大尺寸相当于提供了一层缓存,减少了网络 I/O 的开销;
- 第三,它减少了存储在主服务器上的元数据的大小。这允许我们将元数据保存在内存中。
相应的,大块存储也具有缺点:当小数据量(比如仅仅占据一个 chunk 的文件,文件至少占据一个 chunk)的文件很多时,当很多 GFS Client 同时将 record 存储到该文件时就会造成局部的 hot spots 热点。
Chunk Replication:
为了提高可靠性,每个块都会被复制到多个chunk server上。
MetaData
Master节点存储的元数据包括以下几个方面:
- 块命名空间(Block Namespace):GFS将一个文件划分为多个大小相等的数据块,每个数据块都有一个64位的全局唯一标识符(BlockID),Master节点负责维护块ID与块位置的映射关系。
- 文件命名空间(File Namespace):GFS中的文件由一个全局唯一的文件名和一个文件ID组成,Master节点负责维护文件名和文件ID之间的映射关系。
- 块位置(Block Location):Master节点记录了每个数据块所在的ChunkServer节点的位置信息,以及每个数据块的副本数和副本所在的ChunkServer节点的位置信息。
- 块版本号(Block Version):GFS采用乐观并发控制(Optimistic Concurrency Control)来管理数据块的版本号,每次写操作都会增加数据块的版本号,以保证写操作的原子性和一致性。
- 块状态(Block State):Master节点维护了每个数据块的状态,包括正常状态、丢失状态和过期状态等。如果某个数据块的所有副本都丢失或过期,Master节点会将该数据块的状态标记为丢失状态,并进行相应的处理。
一般来说,元数据是两张Map构成的,第一张是File ID对Chunk ID的一到多的映射;第二张则是Chunk ID对Chunk Server Location的一到多的映射。由于第一张表一般就是查找一个文件的所有块序号,所以使用哈希表存储;第二张由于会发生范围查找(一次查找多个块的存储地址),所以需要使用B+树存储。
In-Memory:
所有的元数据都存放在 Master 的内存中。
这种仅使用内存的方法的一个潜在问题是,块的数量以及整个系统的容量受到主机拥有多少内存的限制。
Chunk Locations:
Master 不保留有关哪个块服务器具有给定块副本的持久记录。
它只是在启动时轮询chunkserver以获取该信息。之后,Master可以保持最新状态,因为它可以控制所有块的放置并通过常规HeartBeat消息监视块服务器的状态。
Operation Log:
操作日志包含关键元数据更改的历史记录。它是GFS的核心。
它不仅是元数据的唯一持久记录,而且还用作定义并发操作顺序的逻辑时间表。
Consistency Model
System Interactions
这部分内容主要描述 Client,Master 和 Chunk Servers 如何交互以实现数据变化,原子记录追加和快照。
Leases and Mutation Order
lease 租约; mutation 修改
Atomic Record Appends
Snapshot
Master Operation
Namespace Management and Locking
Replica Placement
chunk replica placement policy 有两个目的:
- 最大化数据 reliability(可靠性)和 availability(可用性);
- 最大化 network bandwidth utilization(网络带宽利用率);
Creation,Re-replication,Rebalancing
Creation:
Re-replication:
一旦可用副本的数量低于用户指定的目标,主服务器就会重新复制块。
主机选择最高优先级的块,并通过指示某些块服务器直接从现有有效副本中复制块数据来对其进行“克隆”。
放置新副本的目标类似于创建副本的目标:均衡磁盘空间利用率,限制任何单个块服务器上的活动克隆操作,以及将副本分布在机架上。
Rebalancing:
主服务器会定期重新平衡副本:它检查当前副本分发,并移动副本以获得更好的磁盘空间和负载平衡。
Fault Tolerance And Diagnosis
Summary
File System:
文件系统是计算机中一个非常重要的组件,为存储设备提供一致的访问和管理方式。在不同的操作系统中,文件系统会有一些差别,但也有一些共性几十年都没怎么变化:
数据是以文件的形式存在,提供 Open、Read、Write、Seek、Close 等API 进行访问; 文件以树形目录进行组织,提供原子的重命名(Rename)操作改变文件或者目录的位置。
文件系统提供的访问和管理方法支撑了绝大部分的计算机应用,Unix 的“万物皆文件”的理念更是凸显了它的重要地位。
Centralized File System vs Distributed File System:
绝大多数文件系统都是单机的,在单机操作系统内为一个或者多个存储设备提供访问和管理。随着互联网的高速发展,单机文件系统面临很多的挑战:
容量限制:单机文件系统的容量是由本地磁盘的大小所限制的。随着数据量的不断增长,单机文件系统的存储容量很容易就会超过磁盘的承受范围。
性能限制:单机文件系统的性能主要受限于本地磁盘的读写速度和CPU的处理能力。随着数据量的增加和用户访问量的增大,单机文件系统的性能瓶颈很容易就会出现。
可靠性限制:单机文件系统的可靠性主要依赖于本地磁盘的可靠性。如果本地磁盘出现故障,那么文件系统中的数据就有可能会丢失或损坏。
数据共享困难:单机文件系统无法满足多个用户之间的数据共享需求。如果多个用户需要同时访问同一份数据,那么单机文件系统就无法满足这个需求。
随着互联网的高速发展,这些问题变得日益突出,涌现出了一些分布式文件系统来应对这些挑战。
Distributed File System vs Distributed Database:
我在参与CubeFS开源社区的时候,有时候感觉分布式文件系统的设计真的非常类似分布式数据库。二者实际上也确实有一些关联,具体可以查看这个知乎问题。
Distributed File System History:
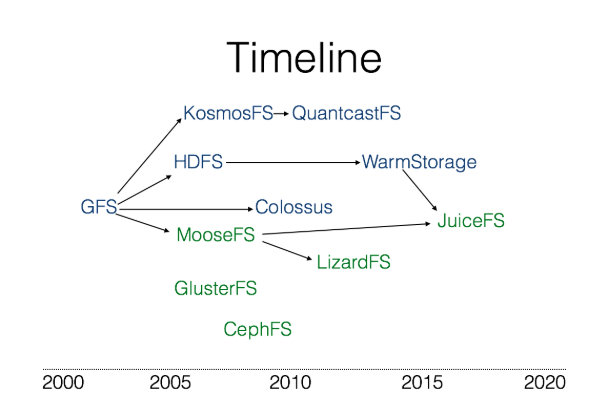
Distributed File System Comparasion:
