
CS231n笔记
这篇博客流水线的记录一下自己学习CS231n的笔记。
Image Classification
图像分类是CV领域中最核心任务之一。它指的是,给定一些标签并将图片预测为一个或多个预定义类别中的过程。
一些潜在的挑战包括:
- Viewpoint variation
- Illumination
- Background Clutter
- Occlusion
- Deformation
Machine Learning: Data-Driven Approach
使用机器学习解决图像分类的流程是:
- 收集数据并定义标签;
- 使用机器学习算法训练分类器;
- 在测试集上评估分类器的准确率。
Nearest Neighbor Classifier
邻近算法的核心思想就是:
- 确定测试实例与每个训练实例的距离(相似程度);
- 从中选择距离最小的那个训练实例,称为"最近的邻居";
- 将测试实例预测为这个"最近邻居"的类别。
值得注意的是,近邻算法是"惰性学习"模型家族的一部分,这意味着它不会根据训练集主动学习或者拟合出一个函数来对新进入的样本进行判断,而是单纯的记住训练集中所有的样本,所以它实际上没有所谓的"训练"过程,而是在需要进行预测的时候从自己的训练集样本中查找与新进入样本最相似的样本,即寻找最近邻来获得预测结果。
Distance Metric:
一些常见的距离度量方法包括:
- L1 Manhattan distance: $d_{L1}(x, y) = \sum_{i=1}^n |x_i - y_i|$
- L2 Euclidean distance: $d_{L2}(x, y) = \sqrt{\sum_{i=1}^n (x_i - y_i)^2}$
k-Nearest Neighbor Classifier:
k邻近算法是使用离待测试点k个最近邻的点来对分类进行预测的一种算法。相比普通最近邻算法只考虑测试实例的单一最近邻居,而k邻域算法考虑测试实例的k个最近邻居。
对于分类问题,k邻域算法通过majority voting的方式从k个最近邻居中获得最常见的类别作为预测类别,即:选择k个邻居中频率最高的类别作为返回值。
Validation sets for Hyperparameter tuning
Hyperparameters:
在机器学习中,超参数是在开始学习过程之前设置用于控制学习过程的参数,而不是通过训练得到的参数数据。比如,在kNN算法中,使用邻居点的数量k和计算距离的distance metric就是超参数。
Cross-validation:
交叉验证在训练集和测试集的基础上,通过进一步将训练数据集随机平均划分为K个互不重叠的子集,然后将其中一个子集作为验证集,其余K-1个子集作为临时训练集。这样循环K次,每次选择一个不同的验证集,其余作为临时训练集,取平均值作为最终估计值。
因为交叉验证可以重复利用原始数据集,较好地评估不同超参数设置下的泛化能力,所以它一般常用来确认和选择模型的超参数。
Linear Classifier
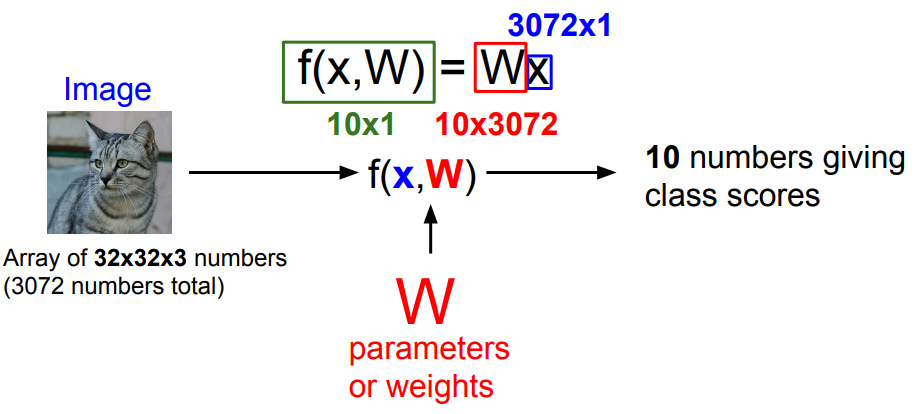
线性分类的方法一般由2个部分组成:决策函数和损失函数。同时,它也是神经网络和卷积神经网络的基础。
Score Function:
决策函数用于对样本进行评分,得到每个类的得分。比如:最简单的线性分类器使用函数$f(x) = w^T x + b$
Loss Function:
损失函数一般是每个样本的平均预测值与真实值的差值,比如:$L = \frac{1}{N} \sum_{i} L_i(f_i(x_i, W), y)$
How To Choose A Good Linear Classifier:
- 定义一个损失函数,用于反映模型预测效果;
- 优化模型参数来减小损失函数的值。
Multiclass SVM Loss
SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值$\Delta$,即:如果正确分类得分大于其余类最高得分+$\Delta$,那么损失函数输出为0;反之,输出。
比如,第i个数据中包含图像$x_i$的像素和代表正确类别的标签$y_i$,其评分函数为$f(x_i, W)$,输出针对所有类别得分的向量。即:第i个数据针对第j个类别的得分就是第j个元素:$s_j = f(x_i, W)_j$。那么,针对第i个数据的多类SVM的损失函数定义如下:
$L_i = \sum_{j\ne y_i}max(0, s_j - s_{y_i} + \Delta)$
一个更直接的例子是,假设一个数据集有三个分类,其中第i个数据经过决策函数得到了分值[13, -7, 11]。已知第i个数据的正确类别是第一个类别,且$\Delta$为10,那么它的损失值为
$L_i = max(0, -7 - 13 + 10) + max(0, 11 - 13 + 10)$
Softmax Classifier
回归 vs 分类:定量输出称为回归,或者说是连续变量预测; 定性输出称为分类,或者说是离散变量预测。
Softmax的作用就是将分类器输出的数值转化为一个概率分布。具体来说:普通分类器的最后一层为线性层,输出为每个类的得分。而Softmax函数将这些得分映射到(0,1)范围内,且保证各类得分和为1。具体公式如下:
$L_i=-f_{y_i} + log(\sum{j}e^{f_i})$
Optimization
优化的目标就是找到能够最小化损失函数值的权重W。
Gradient
梯度是一个向量,它能指出目标函数在各个方向上增长最快的方向。其中每个元素表示某个变量对目标函数的变化影响程度,即:偏导数。对于目标函数F(w)来说,它的梯度可以表示为∇F(w)。
Gradient calculation:
一个是缓慢的近似方法(数值梯度法),但实现相对简单。另一个方法(分析梯度法)计算迅速,结果精确,但是实现时容易出错,且需要使用微分。
Gradient Descent
Backpropagation
回忆之前计算神经网络模型梯度的方法,都涉及到大量微积分计算,并且替换其中某层就需要重新计算。显然,我们需要一种更高效的方法。反向传播正是工程师们给出的答案,它是利用链式法则递归计算表达式的梯度的方法。
Neural Networks
神经网络通常也被称为全连接网络(Fully Connected Network),它指的是神经元层与层之间都是完全连接的,一个层的每个节点都会连接到下一层的每个节点的结构。
一个最基础的两层神经网络可以由线性模型变化而来,比如:
- Linear function: $f = Wx$
- 2-layer Neural Networks: $f = W_2max(0, W_1x)$
Activation functions:
上面的两层神经网络表达式中的max函数也被称为激活函数。它是神经网络区别与普通模型的关键,如果缺少这个函数,上面的模型就变成$f = W_2W_1x$。
一些常见的激活函数包括:
- Sigmoid
- tanh
- ReLU
- Leaky ReLU
- Maxout
- ELU
Convolutional Neural Networks
卷积神经网络和上一章讲的常规神经网络非常相似:它们都是由神经元组成,神经元中有具有学习能力的权重和偏差。每个神经元都得到一些输入数据,进行内积运算后再进行激活函数运算。整个网络依旧是一个可导的评分函数:该函数的输入是原始的图像像素,输出是不同类别的评分。在最后一层(往往是全连接层),网络依旧有一个损失函数(比如SVM或Softmax),并且在神经网络中我们实现的各种技巧和要点依旧适用于卷积神经网络。
它与常规神经网络的不同之处在于卷积神经网络的结构基于一个假设,即输入数据是图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。
Convotional Layer
卷积层是构建卷积神经网络的核心层,它产生了网络中大部分的计算量。
卷积层的深度总是和输入相同。
Pooling Layer
与卷积层类似,汇聚层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为汇聚窗口)遍历的每个位置计算一个输出。 然而,不同于卷积层中的输入与卷积核之间的互相关计算,汇聚层不包含参数。 相反,池运算是确定性的,我们通常计算汇聚窗口中所有元素的最大值或平均值。这些操作分别称为最大汇聚层(maximum pooling)和平均汇聚层(average pooling)。
比如,上图就是一个2*2的最大汇聚操作,以步长为2来对每个深度切片进行降采样,只保留汇聚窗口中的最大值。
它的作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。
Full Connected Layer
在全连接层中,神经元对于前一层中的所有激活数据是全部连接的,这个常规神经网络中一样。它们的激活可以先用矩阵乘法,再加上偏差。更多细节请查看神经网络章节。