
Raft 笔记
简单记录一下学习和实现Raft共识算法(6.824)的笔记。
Raft是一种易于理解的共识算法。它通过保证 复制状态机(Replicated State Machine) 中的日志一致来保证一个分布式系统可靠、复制、冗余和容错。
Basics
在Raft算法中,每一个服务器都是一个复制状态机。每个服务器存储着一份包含命令序列的日志文件,状态机会按顺序执行这些命令。而保证这些日志一致是Raft算法的职责。
一个Raft集群包括若干服务器。服务器一定会处于以下三种状态中的一种:
-
跟随者(Follower):跟随者是被动的,它们不会发送任何请求,只是响应来自领导者和参选者的请求。
-
参选者(Candidate):参选者是参加选举领导者的一台服务器。它是由在一段时间内没有收到任何消息的跟随者转变成的。
-
领导者(Leader):领导者处理所有来自客户端的请求。领导者在它们宕机之前会一直保持领导者的状态。
时间被分为一个个任意不同长度的任期Term,每一个任期的开始都是领导者选举。任期用连续的整数表示。
基本的Raft一致性算法仅需要 2 种RPC。
-
请求选票(RequestVote) 是参选者在选举过程中触发的。
-
增添日志(AppendEntries) 是领导者触发的,为的是复制日志条目和提供一种心跳机制。
此外,Raft算法中主要涉及到两种超时:
-
选举超时(Election Timeout):每个服务器(跟随者)都有长短不一的选举超时。一旦超过这个时间没有接受到来自领导者的消息,那么该跟随者会转化成参选者,进行一次选举。
-
心跳间隔(Heartbeat Timeout):领导者每间隔固定时间向集群中每个服务器发送消息,维护自己领导者地位,避免开启一次新选举。
对于Raft服务器中 日志条目(Log Entry) 的状态,主要分成两种:
-
已提交(Committed):当领导者接收到超过半数服务器复制该日志成功,则会将这条日志记录设置为已提交状态。
-
已执行(Applied):当跟随者更新已提交志后,跟随者会将日志应用到状态机上执行,此时将这条日志设置为已执行状态。
Raft服务器中日志条目至少会记录该日志条目的发生任期(Term)、在整个日志记录中的序号(Index)(从1开始)和状态机需要执行的命令(Command)。
当且仅当两个服务器内,所有日志条目的任期和序号均相等时,称两个服务器日志匹配。

Leader election
Basic leader election procedure
每当一个Raft集群初始化(所有服务器被初始化为跟随者)或该集群中领导者宕机或网络阻塞时,会开始一次新领导者选举:
首先,先到达选举超时的跟随者转化为参选者,并将自己当前的任期加一,并向整个集群所有服务器发送RequestVote请求。
接着,接受到RequestVote请求的服务器,根据任期和日志匹配以及是否还有选票确认是否投票给参选者。具体来说,做以下判断:
-
如果接受到RequestVote请求的服务器任期大于参选者任期,拒绝投票请求,返回false;如果接受到RequestVote请求的服务器任期小于或等于参选者任期,则作进一步判断(注意:如果小于,则还要更新自己的任期并将选票状态刷新为有选票,因为选票和任期同步);
-
如果日志不匹配参选者日志(参选者日志更旧),则返回false;反之,进一步判断。具体流程如下:
-
如果参选者的最后一条日志记录任期号比当前服务器的小,拒绝投票给该参选者,返回false;
-
在最后一条日志记录任期号相同的情况下,如果参选者最后一条日志记录索引号比当前服务器小,拒绝投票给该参选者,返回false。
-
-
如果已经投出票,拒绝投票请求,返回false;反之,投票,重置选举超时计时器,并更新为已无选票状态,返回true。
然后,参选者此时根据选票请求的回复,更新自己的状态。具体来说,做以下判断:
-
如果接受到任期大于自己任期的回复,退出选举、更新自己的任期并重置自己的选举超时计时器。
-
统计有效选票数量,如果数量超过集群服务器总数一半,则选举成功;否则,重置自己的选举超时计时器(重新随机生成一个选举超时时间,避免一直分裂选票)并更新自己的任期,进入新一轮选举。
经过一轮或多轮选举后,成功得到一个领导者,领导者向集群中其余服务器发送AppendEntries请求,确认自己领导地位,保证所有参选者退出选举、跟随者重置选举超时计时器。
除此之外,应当注意的是,在整个选举过程中的任何时间点,如果一个参选者收到大于自身任期的RequestVote请求回复或有效领导者的AppendEntries请求,都将重置选举超时计时器,并退出选举。
Possible situations in leader election
分裂选票Split Vote:多个参选者同时发送RequestVote请求,导致始终没有一个参选者能获得超过半数的选票,赢得选举。Raft算法通过随机选举超时时间来解决分裂选票的问题。
分区领导者掉线重连Rejoin of Partitioned Leader:当某个领导者因为网络问题而无法继续向大多数服务器发送心跳,但它仍然会保持领导者身份,从而出现多领导者情况。此时,提交给旧领导者的日志不会被提交(因为无法被集群大部分服务器复制)。重新加入集群后,旧领导会丢失领导者身份,并删除掉线期间增加的日志。
Log replication
Basic log replication procedure
首先,客户端向Raft集群的领导者发送需要执行的日志条目。领导者接受到该请求后,会将该条目作为参数向其他服务器发送AppendEntries RPC请求。
接着,接受到AppendEntries RPC请求的服务器会根据请求参数,确认当前是否领导者日志匹配。具体做以下判断:
-
如果prevLogIndex大于当前服务器日志长度,则返回false,将conflictIndex设置为当前服务器日志长度,并请求领导者重新发送一次AppendEntries RPC。
-
如果prevLogIndex小于等于当前服务器日志长度且prevLogTerm不等于同位置日志条目的任期,则返回fasle,将conflictIndex设置为当前服务器日志上一任期的最后一条日志序号,并要求领导者重新发送一次AppendEntries RPC请求。
-
如果prevLogIndex小于等于当前服务器日志长度且prevLogTerm等于同位置日志条目的任期,则二者日志匹配。删除后续所有日志条目,并在尾部增添新日志条目。最后,异步将新复制的且领导者已提交的日志条目在状态机上执行。
然后,领导者会根据回复,更新自身状态。具体如下:
-
若返回复制成功(匹配肯定也成功),更新匹配位置;若返回复制失败(匹配也失败),则根据conflictIndex和conflictTerm返回上一个任期的最后一条日志判断。
-
统计成功复制某条目日志的服务器数量,若超过半数服务器成功复制某日志条目,则将其设置为已提交 Committed,并异步将其在状态机上执行。
Optimization in log replication
批处理复制请求Batch and Pipeline:领导者可以缓存一批日志写入,然后一次性发送给跟随者。此外,领导者还可以上一批写入回复之前,直接要求跟随者写入下一批。
并发复制日志Cocurrent Copy:领导者可以先向跟随者发送请求,要求它们复制新日志,再将新日志添加到自己的记录中。这是因为想要将日志条目状态更新为已提交,必须保证提交了该条目服务器数量过半,这与领导者是否复制成功无关。
异步执行Asynchronous Apply:当已提交日志缓存一定时间或数量之后,Raft服务器可以唤醒另一个线程要求执行这一批日志。这是因为已提交的日志可以在任意时间按顺序执行,都不会影响后续的一致性。
Safty
Election restriction
Raft算法中,一个参选者想要从其他服务器中获取选票。除了任期不能小于该服务器任期之外,另一个充分条件是:参选者的日志比本节点的日志更新。具体判断方法:
-
如果参选者的最后一条日志记录任期号比当前服务器的小,拒绝投票给该参选者,返回false;
-
在最后一条日志记录任期号相同的情况下,如果参选者最后一条日志记录索引号比当前服务器小,拒绝投票给该参选者,返回false。
-
反之,该参选者日志足够新,可做进一步判断是否投票给该参选者。
Committing entries from previous terms
如果leader在写入但是还没有提交一条日志之前崩溃,那么这条没有提交的日志是否能提交?答案是不一定。
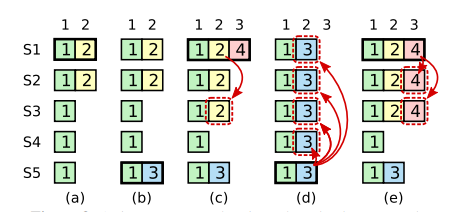
在上图中,流程变化如下:
-
情况a:S1作为领导者向S2复制日志序号2处记录后,S1崩溃;
-
情况b:S5因获得自己、S3和S4选票而上任,成为领导者。它在日志序号2处添加了一条日志记录后崩溃;
-
情况c:S1重启后重新加入集群,再次成为领导者并在日志序号3处添加了一条日志记录后崩溃。
之后可能有两种情况:
-
情况d,S5重启后重新加入集群,成为领导者并覆盖S1、S2和S3日志序号2处记录。
-
情况e,S1重启后重新加入集群,再次成为领导者并将日志序号3处记录复制给S2和S3。
从情况d可知,尽管超过半数的服务器拥有序号为2、任期为2的日志记录,但这条记录仍被覆盖。这说明,提交之前任期的日志记录不依靠统计是否超过半数服务器持有。
Raft算法采用更简单的方法来解决提交之前任期的日志记录的问题。在Raft算法中,只有当前任期的日志经过提交后,可以认为领导者在此之前的任期日志全部已提交。也就是说,只有当前任期的日志经过提交后,才能更新领导者的已提交日志序号。
Log compaction
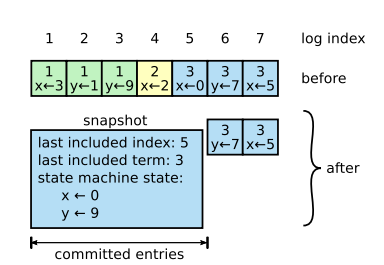
Basic log compaction procedure
在Raft算法中,服务器会隔一段时间删除一段日志,并将待删除日志执行结束后的状态拍照持久化。
当某Raft跟随者因为宕机重连与领导者日志差距太大(领导者已经压缩了它需要复制的日志),此时领导者就会直接向其发生快照。具体流程如下:
-
首先,领导者根据待复制日志是否已被压缩确定是否向跟随者发送快照;
-
接着,领导者从磁盘读取快照并向跟随者发送;
-
然后,跟随者接受到快照,检查是否比自己当前拥有的日志更新:
-
如果不匹配(更旧),拒绝快照复制;
-
反之,删除所有日志,更新已提交和已执行日志序号,持久化当前服务器状态和快照,并将状态机维持到快照描述状态。
-
-
最后,领导者根据复制快照回复判断:
-
若回复中任期大于领导者任期,则领导者丧失领导地位。
-
反之,则认为快照复制成功,更新匹配日志序号。
-